Mining Gravitational Wave Catalogs To Understand Binary Stellar Evolution:
A New Hierarchical Bayesian Framework
by Stephen R. Taylor & Davide Gerosa;
Submitted to Physical Review D on June 21st, 2018.
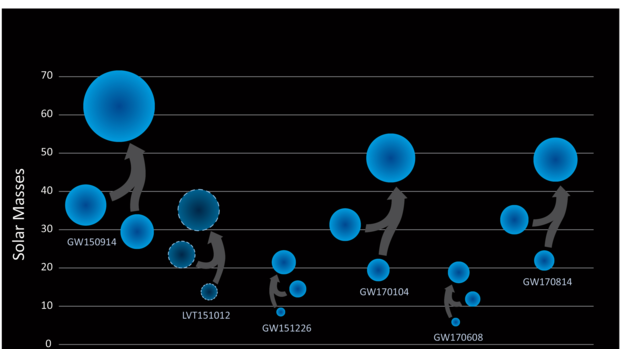
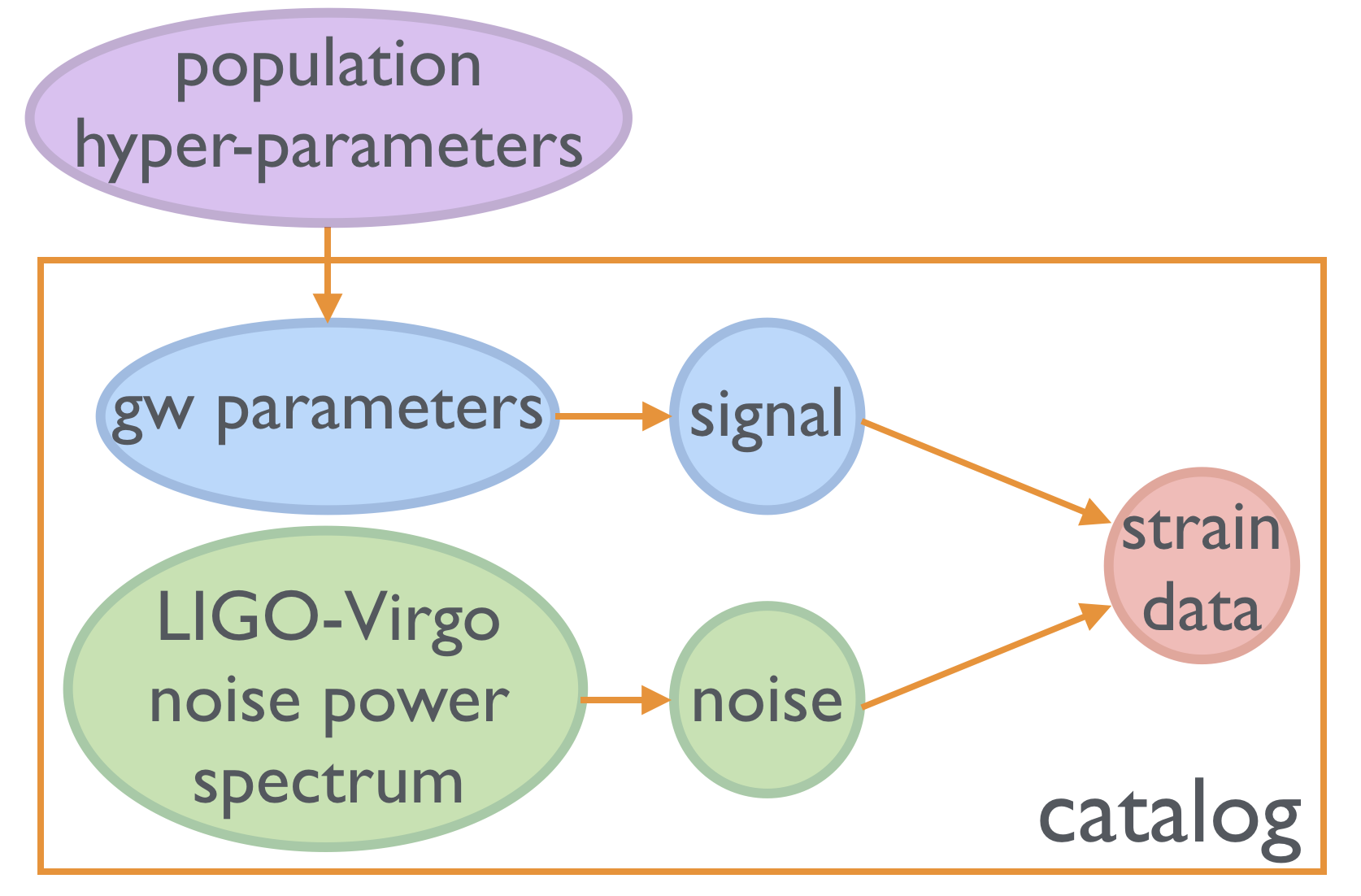
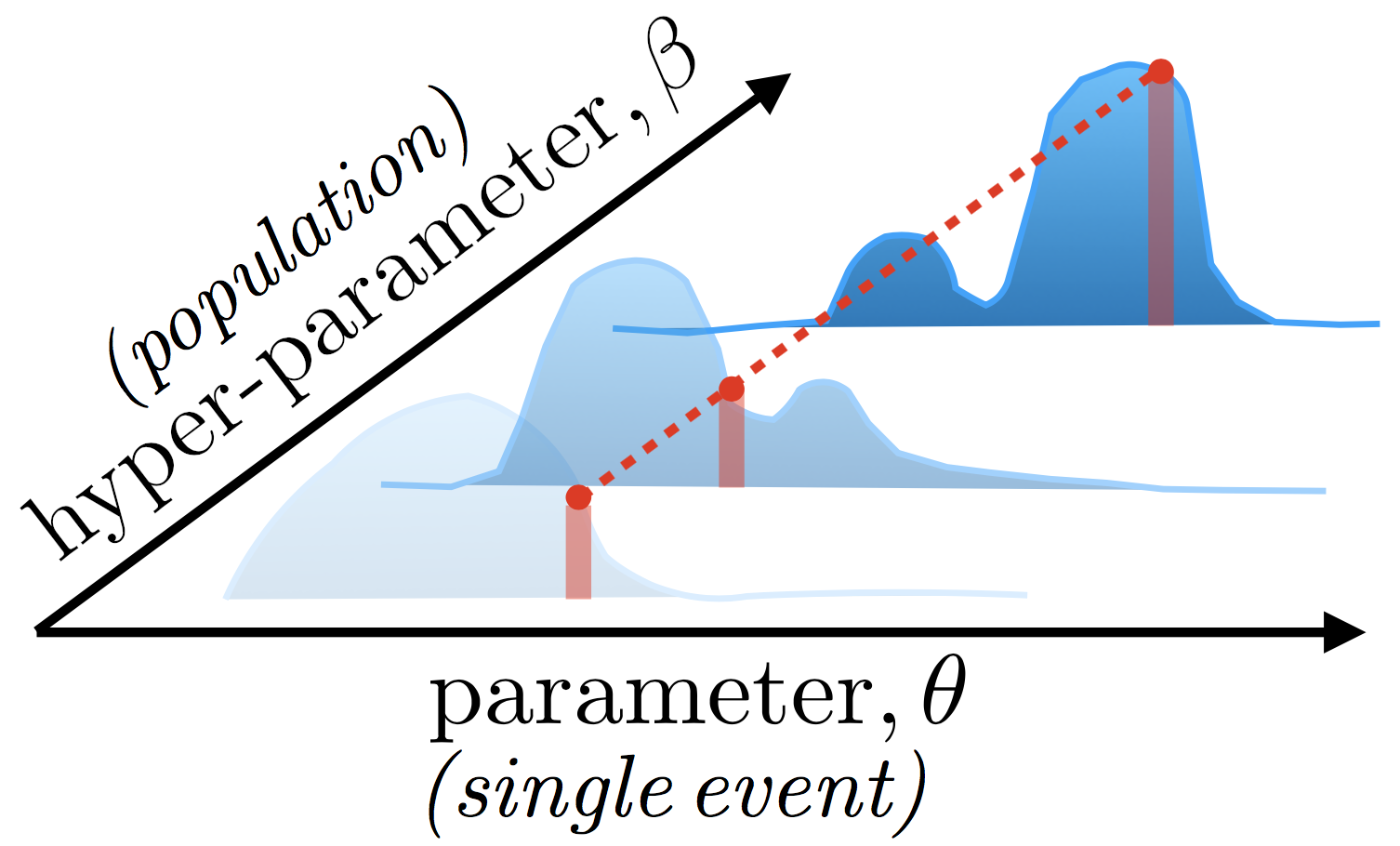
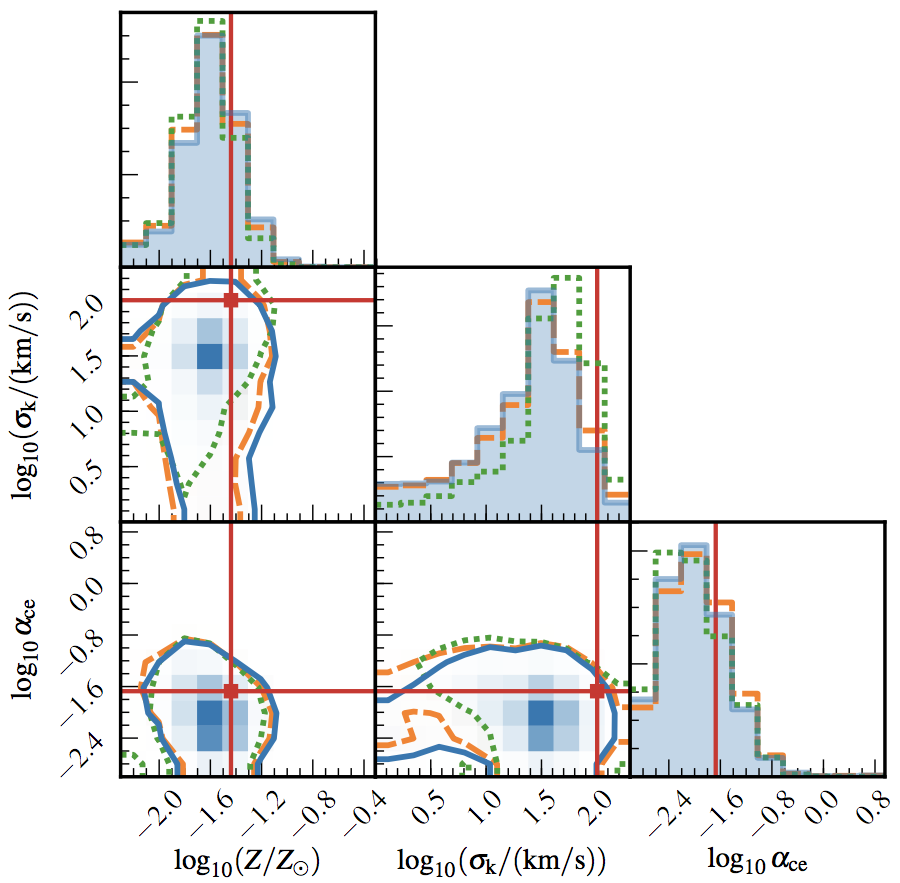
Catalogs of stellar-mass compact binary systems detected by ground-based gravitational-wave instruments (such as LIGO or Virgo) will offer insights into the demographics of progenitor systems and the physics guiding stellar evolution. The masses of existing binary black-hole detections already imply that the metallicity of their progenitor systems must have been sub-solar, and the combination of mass, redshift, spin, and rate information from future detections will further elucidate the underlying astrophysics. Existing techniques approach this through phenomenological models, discrete model selection, or model mixtures. Instead, we explore a technique that uses gravitational-wave catalogs to directly infer posterior probability distributions of progenitor metallicity, kick parameters, and common-envelope efficiency. We use a bank of compact-binary population synthesis simulations to train a Gaussian-process emulator that acts as a prior on observed parameter distributions (e.g. chirp mass, redshift, rate). This emulator slots into a hierarchical population inference framework to extract the underlying astrophysical origins of systems detected by LIGO, Virgo, etc. The method is fast, easily expanded with additional simulations, and can be adapted for training on arbitrary population synthesis codes, and detectors like LISA.
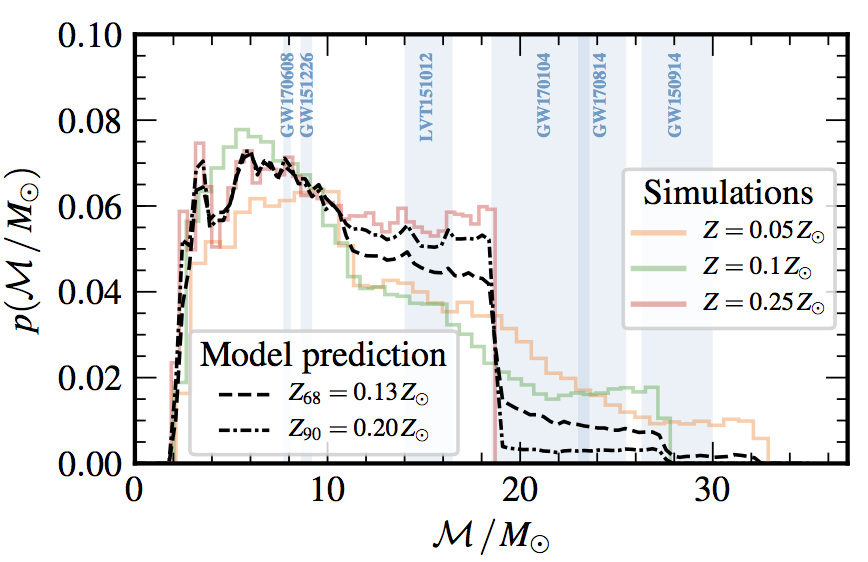
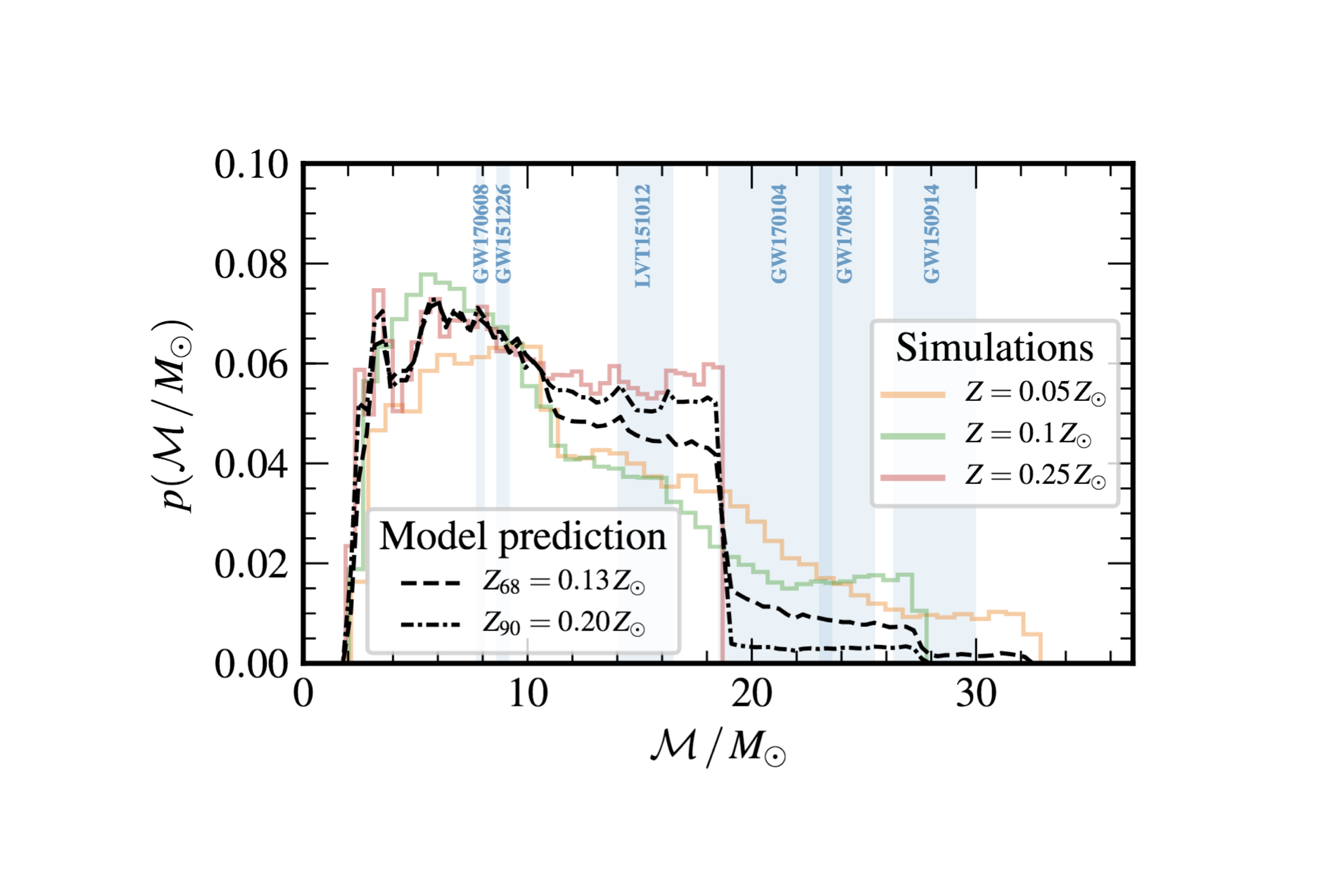 Figure 1: Probability distribution of chirp masses for
Stevenson et al. (2017) training simulations (colored lines)
and our GP-emulator reconstructions (dashed and dash-dot lines).
Figure 1: Probability distribution of chirp masses for
Stevenson et al. (2017) training simulations (colored lines)
and our GP-emulator reconstructions (dashed and dash-dot lines).